Publications
A collaboration with the FDA: new insights using real-world evidence
This latest study applies our method of assessing disease progression in real-world cancer datasets to a large cohort of patients with advanced NSCLC treated with PD-1/PD-L1 inhibitors...

Understanding CDISC Standards: An In-Depth Look at Different Types
| Miscellaneous
Study Data Tabulation Model (SDTM)
The Study Data Tabulation Model (SDTM) is the foundational standard, and perhaps the most widely recognized of all the CDISC standards. It defines a standard structure for clinical trial datasets that are to be submitted to regulatory authorities, such as the U.S. Food and Drug Administration (FDA) and the European Medicines Agency (EMA). SDTM consists of over 50 domains, each corresponding to different types of data collected in a clinical trial. These include, for example:- DM (Demographics) – Data on subject demographics, such as age, sex, and race
- AE (Adverse Events) – Information on adverse events experienced by subjects
- CM (Concomitant Medications) – Details about medications taken by subjects in conjunction with the study treatment
- VS (Vital Signs) – Vital signs measurements, such as blood pressure and temperature
Analysis Data Model (ADaM)
The Analysis Data Model (ADaM) focuses on the creation of datasets that are used for statistical analysis. Built on top of SDTM, which standardizes data collection, ADaM standardizes data analysis. The ADaM datasets are created from STDM, extending the primary results from STDM with calculations specified for the trial analysis. The most common calculation is the determination of how a specific measured characteristic of a trial participant changes over the course of the trial. The calculations are described in specific documents providing the required link between the original data in STDM format and the analysis data in the Adam datasets. Most ADaM datasets align with an SDTM domain. For example:- ADSL (Subject-Level Analysis Dataset) – Contains one record per subject, including demographic and treatment information
- ADAE (Adverse Event Analysis Dataset) – Designed for analyzing adverse event data
Standard for Exchange of Nonclinical Data (SEND)
The Standard for Exchange of Nonclinical Data (SEND) is largely overlapping with SDTM but applies to nonclinical studies. Nonclinical studies, such as animal safety and toxicology studies, are an essential part of the drug development process. The SEND set of standards extends SDTM to include domains specific to the results from these studies. SEND provides a standardized format for nonclinical study data. Some components unique to SEND include:- BW (Body Weights) – Body weight measurements of the test animals
- MA (Macroscopic Findings) – Data on visual observations of the test animals
- OM (Organ Measurements) – A component of pathology data used to assess safety
- SEND-DART (Developmental and Reproductive Toxicology) – A related set of standards specific to the study of the effects of drug candidates on developmental and reproductive health
Clinical Data Acquisition Standards Harmonization (CDASH)
Clinical Data Acquisition Standards Harmonization (CDASH) defines standards for data collection at the clinical trial site. CDASH ensures data collected during a clinical trial is standardized from the very beginning. CDASH specifies the standard data collection fields and formats that should be used in case report forms (CRFs). These include:- Demographics – Standard fields for collecting demographic data
- Adverse Events – Standardized fields for recording adverse events
- Concomitant Medications – Standard formats for capturing medication data
Controlled Terminology
Controlled Terminology refers to the standardized set of terms used across all CDISC standards. This includes predefined lists of allowable values for certain fields, ensuring consistency in data reporting. Controlled Terminology includes dictionaries for various data points, such as:- MedDRA (Medical Dictionary for Regulatory Activities) – Standardized medical terminology for adverse event reporting
- WHO Drug Dictionary – Standardized terms for drug names and classifications
Exploring the Types of Images Digital Pathology Can Reveal
| Miscellaneous
Whole Slide Images (WSI)
Whole slide imaging is the cornerstone of digital pathology. This process involves scanning entire glass slides to create high-resolution digital images that can be viewed, navigated, and analyzed on a computer screen. WSIs provide several benefits:- Comprehensive analysis – Every part of the slide can be examined in detail, ensuring no area is overlooked.
- Remote access – Pathologists can access slides from anywhere, facilitating telepathology and consultations with experts worldwide.
- Enhanced collaboration – Digital slides can be easily shared among colleagues, promoting collaborative diagnostics and research.
Cellular and Tissue Images
Digital pathology allows for the detailed examination of individual cells and tissues, providing insights into their morphology and structure. These images include:- Hematoxylin and eosin (H&E) stained images – These are the most common types of stained slides used in pathology. H&E staining highlights cellular and tissue structures, aiding in the diagnosis of various conditions, including cancers.
- Immunohistochemistry (IHC) images – IHC uses antibodies to detect specific antigens in cells, providing critical information about protein expression patterns. This is particularly useful in identifying types and origins of tumors.
- Fluorescent stained images – Fluorescent stains help pathologists visualize specific components within cells, such as DNA, RNA, and proteins. These images are invaluable in research settings for studying cellular functions and disease mechanisms.
3D Reconstruction Images
Advancements in digital pathology now allow for the creation of three-dimensional reconstructions from two-dimensional slide images. 3D imaging offers several advantages:- Spatial understanding – Pathologists can better understand the spatial relationships among different structures within a tissue.
- Detailed analysis – 3D images provide more detailed information about tissue architecture, which can be crucial in understanding complex diseases.
- Improved diagnostics – This technology can enhance the accuracy of diagnoses by revealing features that might be missed in traditional 2D images.
Dynamic and Interactive Images
Digital pathology isn’t limited to static images. Interactive and dynamic imaging techniques include:- Virtual microscopy – Users can zoom in and out and navigate through digital slides as if using a physical microscope. This enhances the learning experience for medical students and professionals.
- Time-lapse imaging – This involves capturing images at different time points to study dynamic processes, such as cell growth, division, and response to treatments.
- Multiplex imaging – This technique allows for the simultaneous visualization of multiple biomarkers in a single tissue section, providing comprehensive insights into disease pathology.
Computational and AI-Enhanced Images
Artificial intelligence and machine learning are transforming digital pathology by providing computationally enhanced images, which can significantly enhance the efficiency and accuracy of pathology workflows and bioinformatics services. These include:- Quantitative analysis – AI algorithms can quantify various parameters, such as cell count, tissue density, and biomarker expression levels, providing objective and reproducible data.
- Pattern recognition – AI can detect patterns and anomalies in images that might be subtle or missed by the human eye. This is particularly useful in screening for cancers and other diseases.
- Predictive modeling – AI can analyze image data to predict disease outcomes and responses to treatments, assisting in personalized medicine.
Special Stains and Techniques
In addition to traditional H&E and IHC staining, digital pathology supports a variety of special stains and techniques, such as:- Periodic acid-Schiff (PAS) staining – Used to detect polysaccharides and mucosubstances in tissues, aiding in the diagnosis of fungal infections and glycogen storage diseases
- Masson’s trichrome staining – Highlights collagen fibers in tissues, useful in evaluating fibrosis and other connective tissue disorders
- Silver staining – Commonly used to visualize nerve fibers, spirochetes, and reticular fibers in tissues
Data Mining vs. Knowledge Mining: Unraveling the Key Distinctions
| Miscellaneous
Data Mining vs Knowledge Mining
Data mining and knowledge mining aren’t competing approaches but complementary ones. By appreciating the differences between these two processes, organizations can not only understand the present landscape but also shape the future. Data mining is the process of discovering patterns, correlations, and anomalies within large data sets to predict outcomes. By using a combination of statistical analysis, machine learning algorithms, and database management systems, data mining extracts valuable information from raw data. This process is instrumental in various industries, including life sciences and healthcare.Key Components of Data Mining
- Data selection – Identifying the relevant data necessary for analysis, such as scRNA-seq analysis
- Data curation – Removing inconsistencies, duplicates, and errors from the data set to ensure accuracy and reliability
- Data transformation – Converting data into an appropriate format or structure for mining
- Data integration – Combining data from multiple sources into a cohesive dataset
- Data mining – Employing algorithms to identify patterns and relationships
- Pattern validation – Validating the identify patterns on additional datasets to ensure they’re valid and useful
- Knowledge representation – Presenting the discovered knowledge in an understandable and actionable form
Understanding Knowledge Mining
Knowledge mining, on the other hand, goes beyond data mining. While data mining can be seen as the “what” of the data, knowledge mining is the “why” behind it. It involves not only extracting information from data but also synthesizing and contextualizing this information to generate actionable insights and knowledge. This process often incorporates elements of artificial intelligence, natural language processing, and semantic technologies to create a deeper understanding of the data. Knowledge mining could start with results produced by data mining.Key Components of Knowledge Mining
- Data acquisition – Gathering data from various structured and unstructured sources
- Data processing – Cleaning and preparing data for analysis
- Text and semantic analysis – Utilizing natural language processing to understand and analyze text data
- Machine learning and AI – Applying advanced algorithms to learn from data and improve over time
- Knowledge synthesis – Integrating data from different domains to form comprehensive knowledge
- Contextualization – Adding context to the extracted information to make it meaningful and applicable
- Knowledge representation – Displaying the synthesized knowledge in formats that facilitate decision-making, such as dashboards, reports, or visualizations
Differences between Data Mining & Knowledge Mining
Scope & objectives
- Data mining – Focuses primarily on finding patterns and correlations within data sets. Its main objective is to extract valuable information that can be used for predictive analysis.
- Knowledge mining – Goes beyond mere information extraction by creating a comprehensive understanding and actionable knowledge. It seeks to provide context and relevance to the data, enabling more informed decision-making.
Techniques & tools
- Data mining – Utilizes statistical models, machine learning algorithms, and database management tools. Techniques such as clustering, classification, regression, and association rule learning are commonly employed.
- Knowledge mining – Incorporates advanced GenAI and machine learning techniques along with natural language processing (NLP) and semantic technologies. It often uses ontologies, knowledge graphs, and cognitive computing to achieve its goals.
Outcomes & applications
- Data mining – Produces patterns, trends, and predictions that can be used for business intelligence, customer segmentation, fraud detection, and market analysis.
- Knowledge mining – Delivers deeper insights, strategic intelligence, and comprehensive knowledge that can drive innovation, enhance decision-making, and create competitive advantages.
Practical Applications
Data mining
- Healthcare – Predicting and tracking the spread of infectious diseases, aiding in public health planning and response by analyzing patient records. Analyzing patient data to identify the most effective treatments for specific conditions, improving patient outcomes and reducing healthcare costs.
- Life sciences – By mining genetic data, researchers can identify genetic variants associated with specific diseases, helping in the development of personalized medicine.
Knowledge mining
- Healthcare – Knowledge mining techniques can analyze patient data to identify risk factors for diseases and predict outbreaks. This allows for early intervention and preventive measures.
- Life sciences – By integrating genomic data with clinical information scientists can develop personalized treatment plans for patients based on their genetic profiles. This can lead to more effective treatments with fewer side effects.
Challenges & Considerations
Despite their potential, there are ethical implications and technical hurdles to consider in both approaches.Ethical implications
- Privacy concerns – Handling sensitive data with care
- Bias in data – Ensuring algorithms are fair and unbiased
Technical hurdles
- Data quality – Requires high-quality, curated data
- Complexity of analysis – Needs advanced tools and expertise
How FAIR Data Principles Ensure Open & Reproducible Research in Life Sciences
| Miscellaneous
FAIR Data Principles Explained
FAIR is an acronym for Findable, Accessible, Interoperable, and Reusable. These principles were first proposed in a 2016 paper by a group of scientists aiming to promote data management and stewardship in a way that enhances data sharing and reuse (Wilkinson, Dumontier et al. 2016). They emphasize machine-actionability, meaning data should be structured in such a way that it can be automatically found, accessed, and used with minimal human intervention. This is particularly vital as technology, such as that used by bioscience professionals who provide flow cytometry services, continues to evolve with lightning speed.Findability: The First Pillar
Findability refers to the ease with which data can be discovered by both humans and computers. Key aspects include:- Unique identifiers – Assigning a globally unique and persistent identifier to each dataset
- Rich metadata – Describing data with comprehensive metadata that includes the identifier of the data it describes
- Searchable resources – Ensuring data and metadata are registered or indexed in a searchable resource
Accessibility: Ensuring Data Availability
Accessibility means that once data is found, it should be readily retrievable:- Standardized protocols – Using standardized protocols that are open and free to access data by their identifier
- Authentication and authorization – Where necessary, implementing procedures for authentication and authorization
- Persistent metadata – Keeping metadata accessible even if the data is no longer available
Interoperability: Facilitating Data Integration
Interoperability is the ability of data to be integrated with other data in formats that can be used with applications or workflows for analysis, storage, and processing:- Knowledge representation – Utilizing a formal, accessible, shared, and broadly applicable language for knowledge representation
- FAIR vocabularies – Employing vocabularies and ontologies that follow FAIR principles
- Qualified references – Including qualified references to other metadata and data
Reusability: Maximizing Data Value
Reusability ensures data can be reused effectively:- Well-described data – Providing a rich description of the data with accurate and relevant attributes
- Clear usage license – Releasing data with a clear and accessible data usage license
- Detailed provenance – Associating data with detailed provenance
- Community standards – Meeting domain-relevant community standards
Why the FAIR Data Principles Are Important in Life Sciences
Life sciences research involves complex datasets, often derived from experiments, clinical trials, or real world data. The FAIR principles are vital for several reasons:- Enhanced collaboration – FAIR data facilitates collaboration among researchers and institutions. When data is findable and accessible, it’s easier to share insights and resources.
- Improved reproducibility – Reproducibility is a cornerstone of scientific research. By adhering to the FAIR principles, researchers ensure their work can be validated and replicated by others.
- Accelerated innovation – FAIR data allows for the rapid exchange of information, fostering innovation. Scientists can build upon each other’s work without reinventing the wheel.
- Increased transparency – In a world where data-driven decisions are critical, transparency is key. The FAIR principles establish a foundation for open science, promoting trust in research findings.
Implementing FAIR Principles
Implementing the FAIR principles requires careful planning and consideration of the following:- Metadata and data standards – Establishing standards for metadata ensures data can be easily found and understood by others.
- Data licensing – Clear data licensing informs users about what they can and cannot do with the data.
- Data preservation – Ensuring data is stored in secure and sustainable ways so it remains accessible over time.
- Data stewardship – Assigning responsibility for data management to individuals or teams who can oversee the FAIR implementation.
Application of the FAIR Data Principles in Life Sciences
Applying the FAIR data principles in life sciences requires a combination of technical, organizational, and cultural changes. Here are some steps to get started:- Adopt a data management plan (DMP) – A DMP outlines how data will be handled throughout its lifecycle. It includes details on storage, sharing, and archiving practices.
- Use standardized metadata – Metadata provides context for your data, making it findable and reusable. Follow established metadata standards relevant to your field.
- Assign unique identifiers – Ensure your data has unique identifiers like DOIs. This practice not only makes data findable but also tracks its use and citation.
- Choose open and interoperable formats – Opt for data formats that are widely accepted and platform-independent. This choice promotes interoperability and ensures data can be reused across different systems.
- Establish clear access policies – Define who can access your data and under what conditions. Transparent access policies encourage proper data use while protecting sensitive information.
- Create comprehensive documentation – Documentation should be thorough and user-friendly. This includes details about how the data was collected, processed, and any relevant analysis methods.
- Promote a culture of data sharing – Encourage researchers to share their data and recognize those who do. A culture that values data sharing supports the FAIR principles and fosters collaboration.
A Guide to Creating a Data Ontology
| Miscellaneous
Understanding Data Ontology
At its core, a data ontology is a structured representation of concepts within a specific domain and the relationships between them. It serves as a blueprint, guiding how data is organized, accessed, and understood. By defining entities, attributes, and relationships, a data ontology provides a common language for stakeholders, easing communication and collaboration.The Importance of Data Ontology
A well-defined data ontology streamlines communication, facilitates data integration, and enhances data quality. It acts as a common language, fostering collaboration and ensuring consistency across diverse datasets. By establishing a shared understanding of the domain, a data ontology enables organizations to derive meaningful insights, make informed decisions, and drive innovation.Key Components of a Data Ontology
- Conceptualization – Begin by identifying the core concepts relevant to your domain. This involves understanding the entities, attributes, and relationships that define your data landscape. By conducting domain analysis and stakeholder interviews, you can uncover the fundamental concepts that underpin your ontology.
- Taxonomy development – Organize concepts into a hierarchical structure, establishing parent-child relationships that reflect their semantic hierarchy. This taxonomy provides a framework for categorizing and classifying data, facilitating navigation and retrieval.
- Relationship definition – Define the relationships between concepts, specifying how they interact and influence each other. This step elucidates the connections within the data ecosystem, enhancing its comprehensibility and utility. Whether representing hierarchical, associative, or part-whole relationships, clarity and precision are paramount in defining relationships.
- Attribute specification – Describe the properties or characteristics associated with each concept. Attributes define the unique features of entities and provide valuable context for interpreting data. By specifying attributes such as data type, range, and cardinality, you establish a comprehensive understanding of the data landscape.
- Constraints and rules – Establish constraints and rules governing the behavior of concepts and relationships. This ensures data integrity and coherence, preventing inconsistencies and errors. Whether enforcing cardinality constraints, domain restrictions, or integrity rules, explicit constraints contribute to the robustness of the ontology.
Best Practices for Creating a Data Ontology
- Collaborative approach – Involve stakeholders from diverse backgrounds to ensure the ontology reflects the collective understanding of the domain. By soliciting input from domain experts, data analysts, and end users, you can capture a comprehensive view of the domain and promote buy-in across the organization.
- Iterative refinement – Embrace an iterative approach, continuously refining the ontology based on feedback and evolving requirements. By soliciting feedback from stakeholders and incorporating lessons learned from implementation, you can iteratively enhance the ontology’s effectiveness and relevance.
- Reuse existing standards – Leverage existing ontologies and standards whenever possible to avoid reinventing the wheel and promote interoperability. Whether adopting industry standards, domain-specific ontologies, or community-developed vocabularies, reusing existing resources accelerates ontology development and fosters compatibility with existing systems.
- Documentation – Thoroughly document the ontology, including its rationale, design decisions, and usage guidelines. Clear documentation enhances usability and facilitates knowledge sharing. By documenting the ontology’s purpose, scope, and semantics, you empower users to effectively utilize and extend the ontology.
- Validation and testing – Validate the ontology against real-world data and use cases to ensure its effectiveness and correctness. By conducting validation tests, such as consistency checks, satisfiability tests, and domain-specific validation procedures, you verify the ontology’s accuracy and fitness for purpose.
Tools & Technologies for Ontology Development
- Semantic web technologies – RDF (Resource Description Framework), OWL (Web Ontology Language), and SPARQL (SPARQL Protocol and RDF Query Language) provide powerful tools for ontology modeling and querying. By leveraging these standards, you can represent, reason about, and query ontological knowledge in a standardized and interoperable manner.
- Ontology editors – Tools like Protege, TopBraid Composer, and OntoStudio offer intuitive interfaces for creating and managing ontologies. By providing features such as visualization, editing, and ontology debugging, these tools simplify the ontology development process and enhance productivity.
- Graph databases – Graph databases such as Neo4j and Amazon Neptune excel at representing and querying interconnected data, making them well suited for ontology storage and retrieval. By storing ontological knowledge as a graph structure, these databases enable efficient traversal and querying of complex relationships within the ontology.
Challenges & Considerations
- Semantic ambiguity – Addressing semantic ambiguity and reconciling conflicting interpretations can be challenging, requiring careful negotiation and consensus building. By fostering open communication and collaborative decision-making, you can navigate semantic ambiguity and establish shared semantics within the ontology.
- Maintenance overhead – Ontologies require ongoing maintenance to accommodate changes in the domain and evolving data requirements. Adequate resources and processes must be allocated to ensure sustainability. By establishing governance procedures, version control mechanisms, and ontology maintenance workflows, you can mitigate maintenance overhead and ensure the longevity of the ontology.
- Scalability – Ensuring the scalability of the ontology to handle growing volumes of data and evolving complexity is essential for long-term viability. By adopting scalable ontology modeling practices, such as modularization, abstraction, and lazy loading, you can manage ontology complexity and scale gracefully with evolving requirements.
- Interoperability – Harmonizing ontologies across disparate systems and domains is a complex endeavor, necessitating standardization efforts and interoperability protocols. By adhering to established ontology engineering principles, such as modularity, reusability, and alignment, you can promote ontology interoperability and facilitate seamless integration with external systems.
The Transformative Power of Single-Cell Data in Biological Discovery
| Miscellaneous
Applications in Biological Research
- Cellular Heterogeneity Unraveled
- Disease Insights Revealed
- Precision Medicine Advancements
Technological Innovations Driving Single Cell Analysis
- Single Cell Sequencing Platforms
- Computational Algorithms
- Integration with Multi-Omics Data
Challenges and Future Directions
- Data Integration Complexity
- Spatial Transcriptomics
The 3 Vital Stages of Data Curation
| Miscellaneous
Stage 1: Collection and Assessment
The journey of data curation begins with the collection and assessment of raw data from various sources. These sources may include databases, APIs, IoT sensors, social media platforms, and more. Data collection is often a complex undertaking, requiring careful consideration of factors such as data sources, formats, and quality. The key tasks in this stage include:- Identifying relevant data sources
- Ensuring the data is collected ethically and legally
- Performing initial quality checks
- Assessing the data for completeness, accuracy, and relevance
Stage 2: Cleaning and Transformation
Once data is collected, it often requires cleaning and transformation to enhance its quality and usability. This stage, known as data cleaning or data preprocessing, involves identifying and rectifying errors, handling missing or incomplete values, and standardizing data formats. Activities in this phase include:- Removing duplicates and correcting errors
- Standardizing data formats
- Organizing data into structured formats
- Annotating and labeling data for easier access and analysis
- Aligning terms to custom vocabularies or ontologies
Stage 3: Storage and Preservation
Once data is cleaned and transformed, it needs a secure and reliable storage solution. This final stage of data curation involves choosing appropriate storage systems, establishing data security measures, and implementing protocols for data backup and preservation. Key considerations in this stage are:- Ensuring compatibility with existing data systems
- Establishing protocols for data storage and backup
- Implementing data governance policies
- Preparing the data for analysis and application
The Importance of Data Curation
Effective data curation is critical for maximizing the value of data assets and driving informed decision-making. By meticulously managing data throughout its lifecycle, organizations can ensure its accuracy, reliability, and accessibility. This, in turn, enables them to derive meaningful insights, identify trends, and uncover opportunities for innovation and growth.Benefits of Data Curation
- Improved data quality – Curation enhances the quality and reliability of data, making it more trustworthy for analysis and decision-making.
- Enhanced data usability – Well-curated data is easier to access, understand, and analyze, leading to better insights and outcomes.
- Regulatory compliance – Proper data curation ensures compliance with data privacy regulations and industry standards, reducing the risk of legal issues.
- Cost savings – Investing in data curation up front can save costs associated with poor-quality data, such as erroneous decisions or failed projects.
Challenges of Data Curation
- Data volume and variety – Managing large volumes of diverse data can be challenging, requiring robust curation processes and tools.
- Data quality issues – Addressing data quality issues, such as errors and inconsistencies, requires time and resources.
- Data security concerns – Ensuring data security and privacy throughout the curation process is crucial to protect sensitive information.
- Evolving technology – Keeping pace with rapidly evolving technology and data formats requires continuous adaptation and learning.
Understanding the Biological Data Driving Bioinformatics
| Abstract
Types of Biological Data
Biological data can be classified into different types according to their level of organization, complexity, and format. Some of the most common types of biological data are:- Sequence data – This data represents the linear order of nucleotides in DNA or RNA molecules or amino acids in proteins. Sequence data can be used to study the structure, function, and evolution of genes and proteins as well as their interactions and regulation. It can be obtained with various techniques, such as DNA sequencing, RNA sequencing, and mass spectrometry.
- Structure data – This is data that represents the three-dimensional shape and arrangement of atoms or molecules in biological macromolecules, such as proteins, nucleic acids, or protein–nucleic acid complexes. It can be used to study the physical and chemical properties of biological macromolecules as well as their interactions and functions, and it can be obtained with techniques such as X-ray crystallography, nuclear magnetic resonance (NMR), and cryo-electron microscopy.
- Expression data – Expression data measures the amount or activity of genes or proteins in a given biological sample, such as a cell, tissue, or organism. This data can be utilized to examine the gene and protein expression patterns and profiles as well as their regulation and response to various stimuli or conditions. Expression data can be obtained through various methods, including microarrays, quantitative PCR, and proteomics.
- Interaction data – This data identifies and characterizes the physical or functional interactions between biological molecules, such as proteins, nucleic acids, metabolites, and drugs. The data can be employed to study the biological networks and pathways that mediate various biological processes and functions. A variety of techniques can be used to obtain interaction data, including yeast two-hybrid, co-immunoprecipitation, and affinity purification.
- Phenotype data – This is the data that describes the observable characteristics or traits of a biological entity, such as a cell, tissue, organism, or population. Phenotype data is useful for studying the effects of genetic or environmental factors on the morphology, physiology, behavior, or disease susceptibility of biological entities. Microscopy, imaging, and clinical tests are common techniques used to obtain this type of data.
Sources of Biological Data
Biological data can be obtained from various sources, such as:- Experimental data – This is the data generated from laboratory experiments or field studies designed and conducted by researchers to test a specific hypothesis or question. Experimental data can provide direct and reliable evidence for a biological phenomenon or mechanism, but it can also be limited by the availability of resources, time, and ethical constraints.
- Public data – This is data collected and shared by researchers or organizations through public databases or repositories that are accessible online. It can provide a large and diverse amount of information for a biological topic or problem, but it can also be heterogeneous, incomplete, or inconsistent in quality and format.
- Simulated data – This form of data is the product of computational models or simulations based on mathematical or statistical assumptions or rules. Simulated data can provide a theoretical or hypothetical scenario for a biological system or process, but it can also be inaccurate, unrealistic, or oversimplified.
Genomic Data: The Blueprint of Life
At the heart of bioinformatics lies genomic data—the complete set of genes within an organism’s DNA. This data provides a comprehensive blueprint of life, enabling scientists to understand the hereditary information passed from one generation to the next. Genomic data is instrumental in studying the structure, function, evolution, and regulation of genes, unraveling the secrets of our genetic code.Transcriptomic Data: Decoding Gene Expression
While genomic data reveals the genes present in an organism, transcriptomic data unveils how these genes are expressed. It represents the RNA transcripts produced by active genes, shedding light on the dynamic nature of cellular processes. Understanding transcriptomic data is crucial for deciphering the intricate mechanisms that govern various biological functions, helping researchers pinpoint when and where specific genes are active. By obtaining genome-wide transcriptome data from single cells using high-throughput sequencing (scRNA-seq), researchers are able to use scRNA-seq analysis to detect cell subpopulations within certain conditions or tissues.Proteomic Data: Unraveling the Protein Landscape
Proteomic data focuses on the study of proteins, the functional workhorses of cells. This data reveals the types, quantities, modifications, and interactions of proteins within a biological system. By analyzing proteomic data, scientists gain insights into the intricate networks that govern cellular activities. This is particularly valuable in understanding diseases, as aberrations in protein expression or function often underlie pathological conditions.Metabolomic Data: Tracing Metabolic Fingerprints
Metabolomic data provides a snapshot of the small molecules present in a biological system, offering a glimpse into the metabolic activities of cells. This data is crucial for understanding how organisms process nutrients, produce energy, and maintain homeostasis. Metabolomic analysis is especially valuable in studying diseases with metabolic components, such as diabetes or metabolic syndrome.Epigenomic Data: Uncovering the Marks on DNA
Epigenomic data explores the chemical modifications that influence gene expression without altering the underlying DNA sequence. These modifications, such as DNA methylation and histone acetylation, play a pivotal role in regulating various cellular processes. Examining epigenomic data allows researchers to unravel the intricate epigenetic landscape that influences development, aging, and disease.Structural Data: Peering into Molecular Architecture
To truly understand the intricacies of biological systems, scientists rely on structural data. This includes information about the three-dimensional shapes of molecules, such as proteins and nucleic acids. Structural data is essential for elucidating the molecular mechanisms underlying biological processes, facilitating the design of targeted drugs and therapies.Microbiome Data: Exploring the Bacterial Universe Within
The human body is home to trillions of microorganisms collectively known as the microbiome. Microbiome data involves the study of the genetic material of these microbes, providing insights into their diversity, abundance, and functional roles. Understanding the microbiome is crucial for comprehending its impact on human health, from digestion to immune function.Integrative Data: Connecting the Dots Across Domains
In the ever-expanding landscape of bioinformatics, the real power lies in integrating diverse datasets. Integrative data analysis involves combining information from genomics, transcriptomics, proteomics, and more to gain a holistic understanding of biological systems. This multidimensional approach enables researchers to unravel complex biological phenomena and identify novel connections.Harnessing the Power of Biological Data
In the era of precision medicine and personalized therapies, the significance of biological data in bioinformatics cannot be overstated. It serves as the compass guiding researchers through the intricate landscapes of genomics, proteomics, and beyond. As technology continues to advance, the wealth of biological data available will undoubtedly propel scientific discoveries, ushering in a new era of understanding and manipulating the very fabric of life. Decoding the language of biological data opens doors to transformative possibilities, promising a future where we can harness the power of life’s code for the betterment of humanity. If you’re eager to harness the power of comprehensive data management in the life sciences and unlock new possibilities for your research or healthcare initiatives, look no further than Rancho BioSciences. Our bioinformatics services and expertise can propel your projects to new heights. Don't miss the opportunity to take your data-driven endeavors to the next level. Contact Rancho BioSciences today and embark on a journey of innovation and discovery.Exciting News from Rancho BioSciences! We’re thrilled to announce our participation at The 19th Annual Huntington’s Disease Therapeutics Conference! Our team presented 3 groundbreaking posters, contributing to the vital discussions on drug discovery & development. Together, we’re pushing boundaries in Huntington’s Disease research!
| Abstract
Streamlining Research: The Power of CDISC in Data Standardization
| Miscellaneous
CDISC Standards Explained
CDISC standards are a set of rules and specifications that define how to structure, format, and label clinical data and metadata. CDISC standards cover the entire clinical research life cycle, from protocol design and data collection to data analysis and submission. CDISC standards can be grouped into two categories: content standards and data exchange standards. Content standards define what data elements are required or recommended for a given domain or purpose. For example, content standards may specify what variables and values should be included in an adverse events dataset or a clinical trial registry. Data exchange standards define how to represent and transfer data and metadata in a consistent and interoperable way. For example, data exchange standards may specify how to use XML or JSON to encode and exchange data and metadata. Some of the most widely used CDISC standards are:- Protocol Representation Model (PRM) – Defines the elements and structure of a clinical trial protocol
- Clinical Data Acquisition Standards Harmonization (CDASH) – Defines the best practices for collecting and organizing clinical data on case report forms (CRFs)
- Study Data Tabulation Model (SDTM) – Defines the structure and format of clinical data for submission to regulatory agencies
- Analysis Data Model (ADaM) – Defines the structure and format of analysis-ready clinical data for statistical analysis and reporting
- Define-XML – Defines the metadata and documentation of clinical data and analysis datasets in XML format
- Operational Data Model (ODM) – Defines the structure and format of clinical data and metadata for data exchange and integration
The Benefits of CDISC Standards
CDISC standards can bring a variety of benefits to your clinical research, such as:- Ensuring consistency in data collection – CDISC standards provide a common language for data collection, ensuring information is consistently captured across different studies. This standardization enhances data quality and reduces the likelihood of errors, creating a more robust foundation for research outcomes.
- Facilitating interoperability– Interoperability is a key challenge in the realm of clinical research. CDISC standards act as a bridge, enabling interoperability among different systems and stakeholders. This not only expedites data exchange but also facilitates collaborative efforts in multi-center trials.
- Accelerating time to insight – CDISC standards streamline the integration of diverse data sources, eliminating the need for time-consuming data mapping and transformation. This efficiency accelerates the time to insight, allowing researchers, such as those who rely on NGS data analysis, to focus more on analysis and interpretation, ultimately expediting the entire research process.
- Enhancing regulatory compliance – Compliance with regulatory requirements is a critical aspect of clinical research. CDISC standards provide a framework that aligns with regulatory expectations, making it easier for researchers to meet compliance standards. This not only ensures the credibility of the research but also expedites the approval process.
- Improving collaboration and communication – In a collaborative research environment where multiple stakeholders are involved, effective communication is paramount. CDISC standards facilitate clear communication by providing a standardized format for data exchange. This not only fosters collaboration but also minimizes misunderstandings and discrepancies.
- Enabling reusability of data – CDISC standards promote the creation of reusable datasets. Researchers can leverage existing standards, making it easier to share data across studies. This not only saves time but also encourages a more sustainable and cost-effective approach to data management.
- Enhancing data quality and confidence – One of the challenges in data management is ambiguity in data interpretation. CDISC standards address this issue by defining clear data structures and variables. This reduces the chances of misinterpretation, enhancing the overall quality and reliability of the data.
- Improving traceability – CDISC standards enhance traceability by providing a clear lineage of data from its origin to the final analysis. This transparency not only instills confidence in the research findings but also aids in auditing processes, contributing to the overall credibility of the research.
How Is Sequence Data Utilized?
| Miscellaneous
Sequence Data & Bioinformatics
Bioinformatics is the field of science that applies computational methods to biological data, such as DNA, RNA, or proteins. Sequence data is a major form of biological data, as DNA, RNA, and proteins are all sequences of nucleotides or amino acids. It’s used to answer key questions in biology and medicine, such as how sequence variation and cellular levels of RNA and proteins influence physiology and disease. These fundamental questions are addressed through bioinformatics tasks, such as sequence alignment, sequence search, sequence annotation, sequence prediction, and sequence quantification. Sequence Alignment Sequence alignment is the process of arranging two or more sequences to identify regions of similarity or difference. It can be used to measure the evolutionary distance, functional similarity, or structural similarity among sequences. It’s also a key step toward sequencing an individual’s entire genome and quantifying cellular levels of RNA and proteins, as raw sequence data typically comes in the form of fragments which much be mapped to a reference genome, transcriptome, or proteome. Sequence Search Biological function is dictated not just from the literal sequence of DNA, RNA, and proteins, but also from patterns within them. For instance, sequence patterns determine where proteins and small molecules bind to DNA and RNA and where proteins interact with each other. Sequence search attempts to find these patterns, including motifs, domains, and signatures, which improves our understanding of biological function and plays an important role in therapeutics and personalized medicine. Sequence Annotation Sequence annotation adds information and metadata to sequences, including names, descriptions, functions, and locations along a genome. This enriches the understanding and interpretation of sequences and provides useful and accessible information or resources. For instance, sequence annotation can be used to label genes, exons, introns, and promoters in a genome and provide their names, functions, and interactions, which is especially important for downstream analysis. Sequence Prediction Sequence prediction is the process of filling in missing pieces and inferring information about a sequence, such as its structure, function, or evolution. This can be used to complete or improve the knowledge and analysis of sequences and provide novel and valuable insights or hypotheses. For example, sequence prediction can be used to predict the secondary or tertiary structure of a protein, the function or activity of a gene, or the evolutionary origin or fate of a sequence. Sequence Quantification Sequence quantification attempts to determine the levels of sequences present in a biological sample, such as cells and tissues. It relies on upstream bioinformatics tasks, including alignment and annotation, for determining expression levels of specific genes and proteins, and is a critical step toward analysis and interpretation of sequence data.Challenges for Scientists
Bulk and single-cell RNA sequencing are among the most commonly utilized technologies for examining gene expression patterns, both at the population level and the single-cell level. The sheer size of datasets produced by these analyses poses computational challenges in data interpretation, often requiring proficiency in bioinformatic methods for effective data visualization. The constant evolution of sequencing techniques and statistical methods adds an extra element of complexity, often creating a bottleneck for scientists who are eager to delve into RNA-seq datasets but lack extensive coding knowledge to tackle a new software tool or programming language.SEQUIN: Empowering Scientists by Democratizing Data Analysis
In response to these challenges, Rancho BioSciences collaborated with the National Center for Advancing Translational Sciences (NCATS), specifically the Stem Cell Translation Laboratory (SCTL), to develop SEQUIN, a free web-based R/Shiny app designed to empower scientists without bioinformatics services. SEQUIN allows users to effortlessly load, analyze, and visualize bulk and single-cell RNA-seq datasets, facilitating rapid data exploration and interpretation. SEQUIN is designed to serve as a comprehensive tool for the swift, interactive, and user-friendly analysis of RNA sequencing data for single cells, model organisms, and tissues. The integrated functionalities of the app facilitate seamless processes such as data loading, visualization, dimensionality reduction, quality control, differential expression analysis, and gene set enrichment. A key feature of the app enables users to create tables and figures that are ready for publication. As a free resource that’s available to the public, SEQUIN empowers scientists employing interdisciplinary approaches to directly explore and present transcriptome data by leveraging state-of-the-art statistical methods. Consequently, SEQUIN plays a role in democratizing and enhancing the efficiency of probing biological inquiries using next-generation sequencing data at the single-cell resolution level. Rancho BioSciences boasts extensive expertise in delivering services related to RNA-seq data, encompassing transcriptomics analysis, scRNA-seq analysis, clustering, and differential gene expression (DEG) analysis. As part of our innovative Single Cell Data Science Consortium, we’ve established a Four-Tier Data Model tailored for RNA-seq data. Our team has successfully integrated hundreds of datasets, constituting millions of samples. Additionally, Rancho BioSciences has developed atlases organized by therapeutic area and has supported customers with large-scale dataset ingestion workflows. Furthermore, we offer the flexibility to install SEQUIN behind your firewall, allowing for local deployment to meet your specific requirements. If you’re looking for a reliable and experienced partner to help you with your data science projects, look no further than Rancho BioSciences. We’re a global leader in bioinformatics services, data curation, analysis, and visualization for life sciences and healthcare. Our team of experts can handle any type of data, from genomics to clinical trials, and deliver high-quality results in a timely and cost-effective manner. Whether you need to clean, annotate, integrate, visualize, or interpret your data, Rancho BioSciences can provide you with customized solutions that meet your specific needs and goals. Contact us today to learn how we can help you with your data science challenges.The Distinctions between Data Models & Data Ontologies
| Miscellaneous
What Is a Data Model?
A data model is a representation of the structure, format, and constraints of the data in a specific context or application. It defines what kind of data can be stored, how it can be stored, and how it can be manipulated. Data models can be expressed in various ways, such as diagrams, schemas, tables, or code. A data model is usually designed for a specific purpose or use case, such as a database, a software system, or a business process. A data model can be tailored to meet the requirements and expectations of the data’s users and stakeholders, and it can be validated and tested to ensure its quality and consistency. There are different types of data models, depending on the level of abstraction and detail. Some common types are:- Conceptual data model – A high-level overview of the main concepts and entities in a domain and their relationships. It doesn’t specify any technical details or implementation aspects.
- Logical data model – A more detailed and formal representation of the data elements and their properties. It contains the same concepts and relationships as the conceptual data model, but adds details such as data types, cardinality, keys, and constraints. It’s independent of any specific database system or technology.
- Physical data model – A specification of how the data in the logical data model is physically stored and accessed in a particular database system or technology. It includes aspects such as tables, columns, indexes, partitions, views, etc.
- Relational data model – A data model that organizes data into tables with rows and columns and defines the relationships between them using keys and foreign keys.
- XML data model – A data model that represents data as a hierarchical tree of elements, attributes, and text and defines the rules and syntax for the data using schemas and namespaces.
- JSON data model – A data model that represents data as a collection of name-value pairs, arrays, and objects and defines the data using a lightweight and human-readable format.
What Is an Ontology?
An ontology is a formal specification of the concepts, properties, and relationships that exist in a domain of interest. It defines the meaning and semantics of the data and the rules and logic that govern the data. Ontologies can be represented in various ways, such as graphs, languages, or frameworks. An ontology is usually designed to be independent of any specific system. It can capture the common and shared knowledge that exists in a domain and can be used by different kinds of applications or tasks. It can also be linked and aligned with other ontologies to create a network of knowledge. An ontology can be used to:- Provide a common vocabulary and framework for data sharing and integration across different sources and applications
- Enable reasoning and inference over data, such as discovering new facts, validating consistency, or answering queries
- Enhance data quality and usability by adding metadata, annotations, and context to data
- Support data analysis and visualization by enabling semantic queries, filters, and navigation
- FOAF (Friend of a Friend) – An ontology that describes the concepts and relationships related to people, such as name, gender, age, friend, colleague, etc.
- SKOS (Simple Knowledge Organization System) – An ontology that defines the concepts and relationships related to knowledge organization systems, such as thesauri, classifications, taxonomies, etc.
- GO (Gene Ontology) – An ontology that describes the attributes and functions of genes and gene products, such as biological processes, cellular components, molecular functions, etc.
How Do Data Models & Ontologies Differ?
Data models and ontologies are both ways of representing and organizing data, but they differ in several aspects, such as:- Scope – Data models are often application-specific, while ontologies are application-independent. A data model focuses on the data that’s relevant and useful for a particular context or purpose, while an ontology focuses on data from a specific domain or field.
- Expressiveness – Data models have less expressive power than ontologies. Data models can only describe the structure and format of the data, while ontologies can also describe the meaning and semantics of the data. While data models can only define the data elements and their relationships, ontologies can also define the data properties, constraints, rules, and logic.
- Reusability – Data models are less reusable than ontologies. A data model is usually designed for a specific application or system and may not be compatible or interoperable with other applications or systems. An ontology is designed to be reusable and can be linked and integrated with other ontologies to create a network of knowledge.
How Are Data Models & Ontologies Related?
Data models and ontologies are both ways of describing data in a domain or context, but they have different focuses and purposes. Data models focus on the structure and organization of data, while ontologies also include the meaning and semantics of data. Data models are more concerned with how data is stored and manipulated, while ontologies are more concerned with how data is understood and interpreted. Data models and ontologies aren’t mutually exclusive. They can complement each other and work together to provide a comprehensive description of data. For example:- A conceptual data model can be derived from or aligned with an ontology to ensure consistency and coherence among the concepts and entities in a domain.
- A logical or physical data model can be enriched with information from an ontology to add more semantics and metadata to the data elements and their properties.
- An ontology can be derived from or mapped to a logical or physical data model to extract the meaning and context of the data elements and their relationships.
Why Are Data Models & Ontologies Important?
Data models and ontologies are important for effective data management and analysis. They can:- Improve data quality and consistency by defining clear rules and standards for data creation, validation, transformation, and integration
- Enhance data interoperability and reuse by enabling common understanding and communication among different data sources and applications
- Facilitate data discovery and exploration by adding rich metadata, annotations, and context to data
- Support data-driven decision-making by enabling semantic queries, reasoning, inference, and visualization over data
Decoding Data: The Distinctions between Bioinformatics and Data Engineering
| Miscellaneous
Bioinformatics: The Genomic Symphony Conductor
Bioinformatics serves as the conductor of the genomic symphony, orchestrating the analysis and interpretation of biological data. At its core, bioinformatics integrates biology, computer science, and statistics to extract meaningful insights from vast datasets, especially those derived from genomics, proteomics, and other high-throughput technologies. Bioinformatics uses a variety of methods, such as:- Sequence alignment and comparison
- Phylogenetic analysis and evolutionary modeling
- Gene annotation and prediction
- Functional genomics and transcriptomics
- Proteomics and metabolomics
- Structural bioinformatics and molecular modeling
- Systems biology and network analysis
Data Engineering: Building the Infrastructure for Scientific Insights
While bioinformatics focuses on the analysis of biological data, data engineering lays the foundation for efficient data processing and storage. Data engineers design and implement the infrastructure necessary for storing, managing, and accessing vast datasets, ensuring scientists can work with data seamlessly. Data engineering uses a variety of tools and technologies, such as:- Database management systems (SQL, NoSQL, etc.)
- Data integration and transformation tools (ETL, ELT, etc.)
- Data storage and processing frameworks (Hadoop, Spark, etc.)
- Data warehousing and lake solutions (Snowflake, S3, etc.)
- Data quality and monitoring tools (Airflow, Datadog, etc.)
- Cloud computing platforms (AWS, Azure, GCP, etc.)
Divergent Skill Sets: Bioinformaticians vs. Data Engineers
Bioinformaticians: Masters of Algorithms Bioinformaticians require a deep understanding of biology coupled with expertise in algorithm development and statistical analysis. Proficiency in programming languages like Python and R is essential for implementing algorithms that sift through biological data to uncover meaningful patterns and associations. Data Engineers: Architects of Infrastructure Conversely, data engineers are architects of data infrastructure. Their skill set revolves around database management, data modeling, and proficiency in languages like SQL. They design and maintain the systems that enable seamless data flow, ensuring researchers have access to accurate and timely information.Collaboration at the Nexus: Bioinformatics Meets Data Engineering
Interdisciplinary Synergy While bioinformatics and data engineering have distinct roles, their synergy is crucial for advancing life sciences. Collaborative efforts between bioinformaticians and data engineers ensure the analytical tools used by researchers are supported by robust infrastructure, fostering a holistic approach to scientific inquiry. Data Security and Compliance In the life sciences, where data security and compliance are paramount, the collaboration between bioinformatics and data engineering becomes even more critical. Data engineers implement secure data storage solutions, ensuring sensitive information adheres to regulatory standards. Bioinformaticians can then focus on extracting insights without compromising data integrity.The Tapestry of Data Unveiled
In the intricate tapestry of life sciences, bioinformatics and data engineering are threads that, when woven together, create a comprehensive understanding of biological systems. While bioinformatics deciphers the genomic code, data engineering provides the infrastructure for this genomic revelation. Recognizing and appreciating the differences between these disciplines is essential for harnessing their combined potential to propel scientific discovery into uncharted territories. As the fields continue to evolve, the collaboration between bioinformatics and data engineering services will undoubtedly shape the future of life sciences, unraveling the secrets encoded within the vast biological data landscape. Rancho BioSciences can help you with all your data management and analysis needs. Our bioinformatics services and expertise can propel your projects to new heights. As a global leader in data curation, analysis, and visualization for life sciences and healthcare, we’re the experts you can rely on for expert biotech data solutions, bioinformatics services, data curation, AI/ML, flow cytometry services, and more. Don’t hesitate to reach out to us today and see how we can help you save lives through data.Digital Pathology 101: What Life Scientists Need to Know
| Miscellaneous
The Essence of Digital Pathology
At its core, digital pathology involves the digitization of traditional pathology practices. Traditionally, pathologists examine tissue slides under a microscope to diagnose diseases and abnormalities. With digital pathology, this process undergoes a paradigm shift as glass slides are transformed into high-resolution digital images. These digital slides can be viewed, managed, and analyzed using computer technology, fundamentally altering the way pathologists interact with patient samples.Main Components and Technologies
Digital pathology consists of four main components: image acquisition, image management, image analysis, and image communication.- Image acquisition – This is the process of creating digital slides from glass slides using a WSI scanner, a device that captures multiple images of a slide at different focal planes and stitches them together to form a single high-resolution image that can be viewed and manipulated on a computer screen.
- Image management – This involves storing, organizing, and retrieving digital slides using a software application that allows users to access, view, and manipulate digital slides on a computer or mobile device.
- Image analysis – Image analysis is the process of extracting and quantifying information from digital slides using algorithms or models to perform various tasks, such as segmentation, classification, detection, or prediction.
- Image communication – This is the process of sharing and exchanging digital slides and data using a network or a platform—a system that connects users and devices and enables the transmission and reception of digital slides and data.
Benefits of Digital Pathology
Digital pathology has many advantages for life sciences, such as:-
- Improving accuracy – Digital pathology can reduce human errors and biases in diagnosis and research. Image analysis can provide objective and consistent measurements and classifications that can enhance the quality and reliability of pathology data.
- Increasing efficiency – Digital pathology can save time and resources by eliminating the need for physical storage, transportation, and handling of slides. WSI can enable faster scanning and viewing of slides, while image analysis can automate tedious and repetitive tasks.
- Enhancing collaboration – Digital pathology can facilitate communication and collaboration among pathologists and other professionals across different locations and disciplines. WSI can enable remote consultation and education, while image analysis can enable data sharing and integration.
- Advancing innovation – Digital pathology can enable new discoveries and applications in life sciences. Image analysis can provide new insights and biomarkers that can improve diagnosis, prognosis, treatment, and prevention of diseases. WSI can enable new modalities and platforms for pathology education and training.
- Data integration and analysis – Digital pathology generates vast amounts of data that can be leveraged for research purposes. The integration of digital slides with other clinical and molecular data opens avenues for comprehensive analyses, contributing to a deeper understanding of diseases and potential treatment options. This data-driven approach accelerates research efforts, bringing us closer to breakthroughs in medical science.
- Educational innovation – In the realm of education, digital pathology offers a dynamic platform for training the next generation of pathologists. Digital slides can be shared across educational institutions, providing students with a diverse range of cases for learning and examination. This fosters a more interactive and engaging learning experience, preparing future pathologists for the evolving landscape of diagnostic medicine.
Overcoming Challenges and Ensuring Quality
Digital pathology also faces some challenges that need to be addressed, such as:-
- Standardization and regulation – As digital pathology becomes more prevalent, standardization and regulatory measures are crucial to ensure the quality and reliability of digital diagnostic practices. The development of industry standards and guidelines is essential to address concerns related to image quality, data security, and interoperability, fostering trust in the accuracy of digital diagnoses.
- Integration with existing systems – Efficient integration of digital pathology with existing laboratory information systems (LIS) and electronic health records (EHR) is imperative for seamless workflow integration. Overcoming technical challenges and ensuring compatibility will be key to the successful adoption and integration of digital solutions in pathology laboratories.
- Cultural issues – Digital pathology requires a change in the mindset and behavior of pathologists and other stakeholders who are used to traditional methods. These include issues such as training, education, adoption, acceptance, trust, ethics, and responsibility.
The Future of Diagnostics Unveiled
Digital pathology is a dynamic and evolving field with many potential future trends, such as:- Personalized medicine – Digital pathology aligns with the broader shift toward personalized medicine. By combining digital pathology data with molecular and genetic information, healthcare professionals can tailor treatment plans based on an individual’s unique characteristics. This precision approach holds the promise of more effective and targeted therapies, heralding a new era in patient care.
- Artificial intelligence – The integration of artificial intelligence (AI) in digital pathology is a frontier that holds immense potential. AI algorithms can analyze large datasets, identify patterns, and assist pathologists in making more informed diagnoses. As these AI tools continue to evolve, they have the potential to significantly enhance the efficiency and accuracy of pathology workflows and bioinformatics services.
- Democratization and globalization – Increasing and extending the availability of digital pathology can enable the dissemination and distribution of resources and services to various regions and sectors, especially those that are underserved or underdeveloped.
Embracing the Digital Pathway to Healthier Futures
Digital pathology isn’t just a technological evolution. It’s a revolution that’s reshaping the landscape of diagnostics in the life sciences. From precision diagnostics to collaborative research and educational innovation, the impact of this technology is far-reaching. As we navigate the challenges and embrace the opportunities presented by digital pathology, we pave the way for a future where diagnostics aren’t just accurate but also personalized, ushering in a new era of healthcare. If you’re looking for a reliable and experienced partner to help you with your data science projects, look no further than Rancho BioSciences. We’re a global leader in data curation, analysis, and visualization for life sciences and healthcare. Our team of experts can handle any type of data, from NGS data analysis to genomics and clinical trials, and deliver high-quality results in a timely and cost-effective manner. Whether you need to clean, annotate, integrate, visualize, or interpret your data, Rancho BioSciences can provide you with customized solutions that meet your specific needs and goals. Contact us today to find out how we can help you with your data science challenges.Navigating the Realm of Bioinformatics Services
| Miscellaneous
- Sequence Analysis
- DNA sequencing – Assisting in processing and analyzing DNA sequencing data, facilitating tasks such as variant calling, structural variant analysis, and identification of genetic mutations
- RNA sequencing – Analyzing transcriptomic data to understand gene expression patterns, alternative splicing events, and non-coding RNA functionalities
- Structural Bioinformatics
- Predicting protein structures – Aiding in predicting three-dimensional protein structures, offering insights into their functions and interactions
- Drug discovery – Contributing to drug discovery through the analysis of molecular structures, predicting drug-target interactions, and identifying potential candidates
- Comparative Genomics
- Evolutionary analysis – Allowing researchers to compare genomes across different species, identifying evolutionary relationships and conserved regions
- Phylogenetics – Assisting in constructing phylogenetic trees, revealing the relatedness of organisms and their evolutionary history
- Functional Annotation
- Gene ontology analysis – Categorizing genes based on their molecular functions, cellular components, and biological processes
- Pathway analysis – Essential for deciphering the functional implications of genetic and molecular changes by understanding biological pathways and networks
- Biomedical research
- Accelerating genomic research – Expediting the analysis of large-scale genomic datasets, facilitating breakthroughs in understanding genetic contributions to diseases
- Precision medicine
- Personalized treatment plans – Identifying genetic variations influencing individual responses to medications, paving the way for personalized treatment strategies
- Agricultural genomics
- Crop improvement – Contributing to the identification of genes associated with desirable traits in crops, enabling the development of more productive and resilient varieties
- Environmental microbiology
- Microbial community analysis – Enabling the understanding of microbial community diversity and functions, aiding environmental studies and conservation efforts
- Saving time and resources – Outsourcing bioinformatics tasks to experts can reduce the need for hiring, training, and maintaining in-house bioinformatics staff and infrastructure.
- Improving quality and reliability – Using bioinformatics services can ensure the use of state-of-the-art methods and tools that are validated and updated regularly.
- Enhancing collaboration and communication – Sharing bioinformatics results and insights with collaborators and stakeholders can facilitate data exchange and knowledge transfer.
- Advancing innovation and discovery – Applying bioinformatics services can enable new insights and hypotheses that can lead to novel discoveries and applications.
- Expertise – The level of knowledge and experience of the bioinformatics staff in your field of interest
- Quality – The standards and procedures for ensuring the accuracy, reproducibility, and security of the bioinformatics results
- Communication – The frequency and mode of interaction between you and the bioinformatics staff throughout the project
- Flexibility – The ability to customize the bioinformatics service according to your requirements and preferences
- Delivery – The format, content, and timing of the bioinformatics deliverables
- Support – The availability and responsiveness of the bioinformatics staff for providing feedback, troubleshooting, and follow-up
Navigating the Depths: Understanding the Goals of Knowledge Mining
| Miscellaneous
Understanding Knowledge Mining
Knowledge mining is the process of extracting valuable knowledge from vast datasets, both structured and unstructured. It involves utilizing advanced technologies such as artificial intelligence, machine learning, and natural language processing to make sense of the information deluge. The primary objectives of knowledge mining go beyond basic data retrieval. At its core, knowledge mining revolves around deriving meaningful insights and facilitating informed decision-making by establishing connections (references) between and among disjointed pieces of information.Uncovering Hidden Patterns & Trends
One of the key goals of knowledge mining is to reveal hidden patterns and trends within the data. By employing sophisticated algorithms, businesses can identify relationships that might otherwise remain obscured. This enables life sciences professionals to make data-driven decisions and predict potential target liabilities, toxicities, or even efficacies. The utilization of these algorithms allows researchers and scientists to identify correlations, anomalies, and recurring themes, providing valuable insights for accelerating discoveries and breakthroughs.Enhancing Decision-Making Processes
Knowledge mining aims to empower decision makers by providing them with actionable insights. By analyzing historical data and identifying relevant patterns, scientists are able to make decisions about which medicine to advance, the target to focus on, or new assay to implement. This not only enhances the decision-making process but also minimizes risks and enhances overall operational efficiency, which contributes to the smooth progression of life sciences projects.Improving Information Retrieval
Efficient information retrieval is paramount, especially in life sciences research. Knowledge mining creates robust systems that enable scientists and researchers to access relevant information swiftly. The implementation of advanced search algorithms ensures professionals can efficiently navigate through complex datasets, fostering a more agile and responsive research environment.Customizing User Experiences
In the realm of life sciences, customization is key. Knowledge mining facilitates the extraction of insights from diverse data sources, enabling the customization of research approaches. By tailoring experiments and methodologies based on individual project requirements, scientists can ensure a more effective approach to life sciences research.Enhancing Innovation
Innovation is the lifeblood of life sciences research. Knowledge mining acts as a catalyst by providing a deeper understanding of genomics, clinical data, and related processes. By identifying areas for improvement and innovation, organizations can stay at the forefront of life sciences research, fostering a culture of continuous advancement.Detecting Anomalies
In the intricate landscape of life sciences data, knowledge mining plays a crucial role in detecting anomalies that may impact research outcomes. By analyzing vast datasets in real time, organizations can proactively identify irregularities, ensuring the integrity of research findings and maintaining high standards in data quality. As we navigate the intricate landscapes of life sciences, knowledge mining at Rancho BioSciences emerges as a transformative force. Our team’s unparalleled knowledge mining abilities extend beyond data extraction to encompass the transformation of raw information into actionable insights, propelling advancements in genomics, clinical data, and other critical areas. Embracing these objectives positions Rancho BioSciences at the forefront of life sciences research, equipped with the insights needed to accelerate discoveries, foster innovation, and make lasting contributions to the field. To learn more about our vast array of services, from knowledge mining to flow cytometry analysis, call us today.FAIR Data: What It Is & Why It Matters
| Miscellaneous
FAIR Data Defined
FAIR represents a set of guiding principles aimed at maximizing the value of data. Developed by a group of international experts representing academia, industry, and publishing, FAIR data principles serve as a roadmap for data management, ensuring information is well organized and easy to discover, access, share, and reuse.Findability: Navigating the Data Maze
The first pillar of FAIR emphasizes the importance of making data findable by both humans and computer systems. In the vast ocean of digital information, finding relevant data can be akin to searching for a needle in a haystack. FAIR data principles advocate for the use of unique identifiers, metadata, and standardized vocabularies to enhance discoverability and ensuring data is indexed and searchable. This ensures researchers and analysts can efficiently locate the data they need, saving time and resources.Accessibility: Breaking Down Data Silos
Even the most valuable data is rendered useless if it remains inaccessible. Accessibility is the second pillar of FAIR, encouraging the removal of barriers that hinder data retrieval. This involves providing open access to data, eliminating restrictions, and employing clear and comprehensive access protocols. It also ensures data can be retrieved in a usable format. FAIR data promotes inclusivity, allowing a broader audience to benefit from shared information and fostering collaborative research efforts.Interoperability: Bridging the Data Divide
Interoperability, the third pillar of FAIR, addresses the challenge of integrating diverse datasets from various sources. In the absence of standardized formats and structures, data silos emerge, hindering cross-disciplinary collaboration. FAIR data principles advocate for the use of common data models and standards, as well as providing clear data interfaces and APIs to facilitate seamless integration. This interoperability ensures data can be combined and analyzed cohesively, unlocking new insights and promoting a holistic understanding of complex phenomena.Reusability: Maximizing the Life Span of Data
The fourth and final pillar of FAIR focuses on reusability, acknowledging that data shouldn’t have a single-use purpose. By ensuring data is well documented, including clear methodologies and contextual information, FAIR principles enable others to reuse the data in new analyses and studies. This not only maximizes the value of the original research but also promotes a sustainable approach to data management.Examples of FAIR Data
There are many examples of FAIR data initiatives and projects across different domains and disciplines. Here are some of them:- The European Open Science Cloud (EOSC) – a federated infrastructure that provides access to open and FAIR data and services for research and innovation in Europe.
- The Global Biodiversity Information Facility (GBIF) – an international network that provides access to biodiversity data from natural history collections, research projects, citizen science initiatives, and more.
- The Human Cell Atlas (HCA) – an international consortium that aims to create a comprehensive reference map of all human cells using single-cell technologies and FAIR data practices.
- The COVID-19 Data Portal – a platform that enables the sharing and analysis of COVID-19 related datasets from different sources and domains using FAIR data principles.
The Impact of FAIR Data on Scientific Research
FAIR data principles are transforming the landscape of scientific research. With increased findability, accessibility, interoperability, and reusability, researchers can build upon existing knowledge more efficiently. Collaboration among scientific communities is enhanced, leading to accelerated discoveries and breakthroughs. FAIR data principles also contribute to the reproducibility of research, a cornerstone of scientific integrity, by ensuring the data underpinning studies is transparent and accessible.FAIR Data in Business: A Competitive Edge
Beyond the realm of academia, businesses are recognizing the transformative power of FAIR data. In a data-driven economy, organizations that harness the full potential of their data gain a competitive edge. FAIR principles enable businesses to streamline their data management processes, break down internal data silos, and extract meaningful insights. This, in turn, enhances decision-making, drives innovation, and ultimately contributes to the bottom line.Future Challenges for FAIR Data
While the adoption of FAIR data principles is gaining momentum, challenges persist. Implementation can be resource intensive, requiring investment in infrastructure, training, and cultural shifts. Additionally, issues related to privacy, data security, and ethical considerations must be carefully navigated. As technology, such as that used by professionals who provide flow cytometry services, continues to evolve, the FAIR principles themselves may require updates to remain relevant and effective. In a world inundated with data, the importance of effective data management cannot be overstated. FAIR data principles provide a comprehensive framework for ensuring data isn’t only managed efficiently but also utilized to its full potential. Whether in scientific research, business analytics, or technological innovation, the adoption of FAIR principles marks a crucial step toward a future where knowledge is truly unlocked and accessible to all. Maximize the potential of comprehensive data management in life sciences and unlock new opportunities for your research or healthcare initiatives by exploring the transformative capabilities of Rancho BioSciences. Our bioinformatics services and expertise can propel your projects to unparalleled success. Take the opportunity to take your data-driven endeavors to the next level. Contact Rancho BioSciences today and embark on a journey of innovation and discovery.Unlocking the Secrets of Life: A Deep Dive into Single-Cell Bioinformatics
| Miscellaneous
Single-Cell Bioinformatics Defined
At its core, single-cell bioinformatics is a multidisciplinary field that combines biology, genomics, and computational analysis to investigate the molecular profiles of individual cells. Unlike conventional approaches that analyze a population of cells together, single-cell bioinformatics allows researchers to scrutinize the unique characteristics of each cell, offering unprecedented insights into cellular diversity, function, and behavior.The Power of Single-Cell Analysis
Unraveling Cellular Heterogeneity
One of the key advantages of single-cell bioinformatics is its ability to unveil the intricacies of cellular heterogeneity. In a population of seemingly identical cells, there can be subtle yet crucial differences at the molecular level. Single-cell analysis enables scientists to identify and characterize these variations, providing a more accurate representation of the true biological landscape.Mapping Cellular Trajectories
Single-cell bioinformatics goes beyond static snapshots of cells, allowing researchers to track and understand dynamic processes such as cell differentiation and development. By analyzing gene expression patterns over time, scientists can construct cellular trajectories, revealing the intricate paths cells take as they evolve and specialize.The Workflow of Single-Cell Bioinformatics
Cell Isolation & Preparation
The journey begins with the isolation of individual cells from a tissue or sample. Various techniques, including fluorescence-activated cell sorting (FACS) and microfluidics, are employed to isolate single cells while maintaining their viability. Once isolated, the cells undergo meticulous preparation to extract RNA, DNA, or proteins for downstream analysis.High-Throughput Sequencing
The extracted genetic material is subjected to high-throughput sequencing, generating vast amounts of data. This step is crucial for capturing the molecular profile of each cell accurately. Advances in sequencing technologies, such as single-cell RNA sequencing (scRNA-seq) and single-cell DNA sequencing (scDNA-seq), have played a pivotal role in the success of single-cell bioinformatics.Computational Analysis
The real power of single-cell bioinformatics lies in its computational prowess. Analyzing the massive datasets generated during sequencing requires sophisticated algorithms and bioinformatics tools. Researchers employ various techniques, including dimensionality reduction, clustering, and trajectory inference, to make sense of the complex molecular landscapes revealed by single-cell data.Applications Across Biology & Medicine
Advancing Cancer Research
Single-cell bioinformatics has revolutionized cancer research by providing a detailed understanding of tumor heterogeneity. This knowledge is crucial for developing targeted therapies tailored to the specific molecular profiles of individual cancer cells, ultimately improving treatment outcomes.Neuroscience Breakthroughs
In neuroscience, single-cell analysis has shed light on the complexity of the brain, unraveling the diversity of cell types and their functions. This knowledge is instrumental in deciphering neurological disorders and developing precise interventions.Precision Medicine & Therapeutics
The ability to analyze individual cells has immense implications for precision medicine. By considering the unique molecular characteristics of each patient’s cells, researchers can tailor treatments to maximize efficacy and minimize side effects.Challenges & Future Directions
While single-cell bioinformatics holds immense promise, it’s not without challenges. Technical complexities, cost considerations, and the need for standardized protocols are among the hurdles researchers face. However, ongoing advancements in technology and methodology are gradually overcoming these obstacles, making single-cell analysis more accessible and robust. Looking ahead, the future of single-cell bioinformatics holds exciting possibilities. Integrating multi-omics data, improving single-cell spatial profiling techniques, and enhancing computational tools will further elevate the precision and depth of our understanding of cellular biology. As we navigate the frontiers of biological research, single-cell bioinformatics stands out as a transformative force, unlocking the secrets encoded within the microscopic realms of individual cells. From personalized medicine to unraveling the complexities of diseases, the applications of single-cell analysis are vast and promising. As technology advances and researchers continue to refine their methods, the insights gained from single-cell bioinformatics will undoubtedly shape the future of biology and medicine, offering a clearer and more detailed picture of life at the cellular level. If you’re looking for a reliable and experienced partner to help you with your data science projects, look no further than Rancho BioSciences. We’re a global leader in data curation, analysis, and visualization for life sciences and healthcare. Our team of experts can handle any type of data, from NGS data analysis to genomics and clinical trials, and deliver high-quality results in a timely and cost-effective manner. Whether you need to clean, annotate, integrate, visualize, or interpret your data, Rancho BioSciences can provide you with customized solutions that meet your specific needs and goals. Contact us today to find out how we can help you with your data science challenges.How Data Management Enhances Life Sciences Research
| Miscellaneous
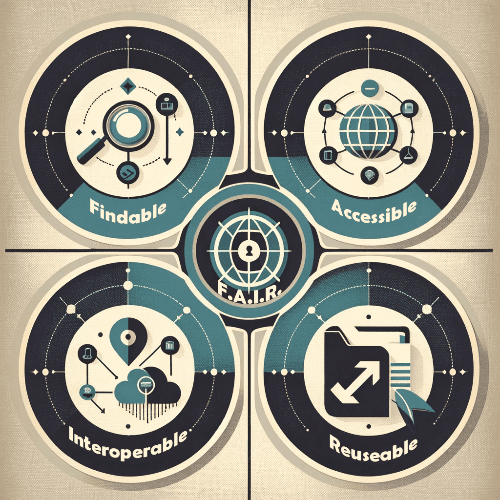 Data management involves collecting, organizing, storing, and sharing data in a way that ensures it’s Findable, Accessible, Interoperable, and Reusable (F.A.I.R.). This is crucial in any field where data is the key for making decisions, solving problems, or advancing knowledge. In life sciences, the importance of data management is even more pronounced due to the complex and diverse nature of the voluminous data involved.
The term “life science” encompasses diverse disciplines like biology, biotechnology, pharmacology, medicine, and more. These fields generate data from various sources, such as experiments, observations, simulations, surveys, clinical trials, and literature. This data can take many forms—it might be structured or unstructured, quantitative or qualitative, static or dynamic, and it can vary in size, format, and quality.
In life sciences, the sheer amount of data has revolutionized research and knowledge creation. Data management is at the heart of this revolution, as it is vital for making sense of the vast information generated in these fields. As we continue, we’ll delve deeper into the fascinating world of data management in life sciences and the essential role it plays.
Data management involves collecting, organizing, storing, and sharing data in a way that ensures it’s Findable, Accessible, Interoperable, and Reusable (F.A.I.R.). This is crucial in any field where data is the key for making decisions, solving problems, or advancing knowledge. In life sciences, the importance of data management is even more pronounced due to the complex and diverse nature of the voluminous data involved.
The term “life science” encompasses diverse disciplines like biology, biotechnology, pharmacology, medicine, and more. These fields generate data from various sources, such as experiments, observations, simulations, surveys, clinical trials, and literature. This data can take many forms—it might be structured or unstructured, quantitative or qualitative, static or dynamic, and it can vary in size, format, and quality.
In life sciences, the sheer amount of data has revolutionized research and knowledge creation. Data management is at the heart of this revolution, as it is vital for making sense of the vast information generated in these fields. As we continue, we’ll delve deeper into the fascinating world of data management in life sciences and the essential role it plays.
A Historical Perspective
 ⦁ A Decade Ago – Our journey began with a focus on centralized databases and data security. This was the industry standard, focusing more on storage than analytics.
⦁ Three Years Ago – We witnessed a shift toward cloud technologies and compliance measures, with AI Machine Learning beginning to play a role in basic analytics.
⦁ Present Day – Today, our emphasis is on real-time data analysis, AI-driven automation, and advanced knowledge mining. This represents a significant evolution from mere data storage to transforming data into actionable intelligence.
⦁ A Decade Ago – Our journey began with a focus on centralized databases and data security. This was the industry standard, focusing more on storage than analytics.
⦁ Three Years Ago – We witnessed a shift toward cloud technologies and compliance measures, with AI Machine Learning beginning to play a role in basic analytics.
⦁ Present Day – Today, our emphasis is on real-time data analysis, AI-driven automation, and advanced knowledge mining. This represents a significant evolution from mere data storage to transforming data into actionable intelligence.
Understanding Data Management in Life Sciences
Data management in the life sciences involves the collection, storage, organization, and analysis of data relevant to biological and biomedical research. It encompasses a wide range of data types, including genomics, proteomics, clinical data, imaging data, and more. The aim is to ensure this multi-modal data is effectively captured, securely stored, and readily accessible for analysis, thereby facilitating scientific discoveries and advancements in healthcare.Guiding Clients Through Their Data Management Journey
⦁ For Startups and Growing Companies – In the early stages, we assist clients in transitioning from basic data storage solutions to more sophisticated data management systems. Our expertise in effective data management helps these organizations unlock actionable insights, vital for their growth and development. ⦁ Scaling Up with AI-Driven Data Automation – As our clients expand, we introduce AI-driven automation to streamline their data processing and analysis. This transition is crucial for handling the increasing volume and complexity of data, turning it into a valuable asset for their operations. ⦁ Establishing a Robust Data Fabric for Global Entities – For clients with a global presence, we focus on building a seamless data fabric. This ensures data accessibility and integrity across different geographic locations and regulatory environments, supporting their international operations. ⦁ Empowering Research with Knowledge Mining – At every step, we delve into knowledge mining to bolster our clients’ research and development initiatives. Our services enable them to make informed decisions based on comprehensive and insightful data analysis.The Data Deluge
The life sciences are in the midst of a data deluge. Rapid advancements in technologies like DNA sequencing, mass spectrometry, and imaging have enabled researchers to generate vast amounts of data. Genomic sequencing is a prime example of the data-intensive nature of modern life sciences. A single experiment in this field can generate terabytes of data, presenting a substantial challenge in data management. Effectively handling this vast influx of data necessitates specialized approaches and talented experts to ensure accuracy, efficiency, and utility of the data.Challenges in Data Management
There are several significant challenges in the field of data management in life sciences: ⦁ Data acquisition – Obtaining data from various sources, such as experiments, observations, simulations, literature, or databases, can be challenging due to the diversity, complexity, and volume of data as well as the need for standardization and validation of data formats and protocols. ⦁ Data curation – Enhancing, annotating, and documenting data to make it more understandable and reusable can be challenging because of the dynamic and evolving nature of data along with the need for interoperability and integration of data across different domains and platforms. ⦁ Data storage – Preserving and securing data in appropriate locations and formats can be difficult due to the high cost and maintenance of data infrastructure and the need for scalability and reliability of data access and backup. ⦁ Data analysis – Applying statistical, computational, or visual methods to extract insights and knowledge from data is often challenging due to the heterogeneity, uncertainty, and noise of data as well as the need for innovation and collaboration of data methods and tools. ⦁ Data sharing – Disseminating and communicating data to relevant stakeholders, such as researchers, clinicians, regulators, or patients, can be a challenge because of the ethical, legal, and social implications of data disclosure as well as the need for transparency and reproducibility of data results. With regulations like GDPR and HIPAA, ensuring data privacy and compliance is a top priority in life sciences. To address these challenges and support data management in life sciences, there are various services and solutions available, such as: ⦁ Data governance frameworks – These are frameworks, such as data models, vocabularies/ontologies, and policies that provide guidelines for ensuring the quality, interoperability, security, privacy, and ethics of data. Data governance frameworks can help with tasks such as data ownership, stewardship, provenance, consent, and compliance. ⦁ Bioinformatics services – These are services that provide specialized expertise and resources for managing and analyzing biological data. ⦁ Bioinformatics services can help with tasks such as genome sequencing, gene expression analysis, protein structure prediction, phylogenetic analysis, and drug discovery. ⦁ Data repositories – These are the data hub repositories that provide online access and storage for curated and standardized data sets. Data repositories can help with tasks such as data discovery, retrieval, citation, and reuse. ⦁ Data management platforms – These are platforms that provide integrated software and hardware solutions for storing and processing large-scale data. Data management platforms can help with tasks such as data ingestion, transformation, querying, visualization, and mining.Tailoring Solutions for Pharma/Biotech
⦁ Research and Development (R&D) – In the R&D domain of Pharma/Biotech, our data management solutions are crafted to accelerate drug discovery and innovation. We focus on managing data from early-stage research, laboratory experiments, and preclinical studies. Our services ensure efficient handling of experimental data, fostering an environment where innovation thrives. ⦁ Manufacturing – In the manufacturing sector of Pharma/Biotech, our attention turns to managing data related to production processes, quality control, and supply chain logistics. We provide robust solutions to ensure data integrity and compliance with manufacturing standards, essential for maintaining product quality and safety. ⦁ Clinical Trials – For clinical trials, our data management approach is designed to handle the complexities of trial data. This includes patient data management, trial results, and regulatory compliance documentation. Our services support the efficient and secure management of clinical trial data, ensuring patient safety and the reliability of trial outcomes.Tailoring Solutions for Biobanks
⦁ Biobanking – Our data management solutions for biobanks emphasize the preservation, cataloging, and retrieval of biological samples. We focus on ensuring the integrity and traceability of data related to these samples. This supports the critical research activities in Pharma/Biotech, facilitating the accessibility of high-quality data for groundbreaking research and development.Benefits of Effective Data Management
Implementing effective data management offers numerous benefits: ⦁ Accelerated research – Researchers can access and analyze data more rapidly, expediting discoveries and drug development. ⦁ Enhanced collaboration – Well-organized data facilitates collaboration among research teams, even those working remotely or across borders. ⦁ Cost reduction – Efficient data management can reduce costs associated with data errors, redundancy, and inefficient use of resources. ⦁ Improved patient care – In healthcare, data management aids in personalized medicine by analyzing patient data to tailor treatments and interventions. ⦁ Scientific advancements – The foundation for new scientific knowledge and innovations is built on the robust management of data, allowing scientists to make breakthroughs in various life science fields. Data management in life sciences is at the heart of modern scientific research. It not only empowers researchers to make groundbreaking discoveries but also enhances healthcare and fosters collaboration in the global scientific community. As data continues to accumulate at an unprecedented pace, the role of data management remains central to unlocking the secrets of life’s most intricate processes. At Rancho Biosciences, our expedition in data management is about more than just navigating the complexities of data. It’s about empowering our clients to realize their goals in the life sciences sector. By providing bespoke data management solutions, we turn data into a strategic asset, driving innovation and accelerating scientific discoveries. We invite you to partner with us on this journey, harnessing our expertise to unlock the potential of your data and propel your projects to success. Don’t miss the opportunity to take your data-driven endeavors to the next level. Contact Rancho BioSciences today at (760) 642-6133 and embark on a journey of innovation and discovery.Unlocking the Secrets of Life: Bioinformatics & Its Applications
| Miscellaneous
Bioinformatics Defined
Bioinformatics is a multidisciplinary field that bridges biology, computer science, and mathematics. Its primary goal is to make sense of the massive volumes of biological data generated by modern scientific techniques. Researchers in this field use a combination of software, algorithms, and databases to store, analyze, and interpret biological data, from DNA sequences to protein structures.Genome Sequencing & Analysis
One of the most renowned applications of bioinformatics is genome sequencing and analysis. Scientists use advanced sequencing technologies to determine the order of nucleotides in DNA. Bioinformaticians then step in to process this vast amount of genetic information. By comparing and analyzing genomes, they can identify genes, regulatory elements, and mutations associated with various diseases, ultimately contributing to advancements in personalized medicine and genetic research.Proteomics & Structural Biology
Bioinformatics isn’t limited to genetics alone—it extends its reach to proteomics and structural biology as well. Proteomics aims to understand the functions and interactions of proteins within cells. By combining experimental data with computational methods, scientists can uncover protein-protein interactions and predict protein structures, with significant implications for understanding diseases. One of the main applications of proteomics is drug discovery, which is the process of finding new compounds that can modulate biological targets for therapeutic purposes. For example, bioinformatics can help to:- Discover new targets for drugs based on their role in disease pathways
- Screen potential drugs for their binding affinity and specificity to targets
- Design new drugs based on their structure and properties
- Test drugs for their efficacy and toxicity in cells and animals
Phylogenetics & Evolutionary Biology
Studying the evolutionary relationships between species is another crucial application of bioinformatics. Phylogenetics, the field devoted to this purpose, utilizes computational tools to analyze DNA, RNA, and protein sequences to construct evolutionary trees. This aids in deciphering the origin and diversification of species, tracking the spread of diseases, and understanding how life on Earth has evolved over billions of years.Metagenomics & Microbiome Studies
Bioinformatics not only analyzes data from humans and individual model organisms, but it also samples containing material from multiple species living together in a particular environment. Microbiomes and the bioinformatics subfield of metagenomics help us understand the role microorganisms play in various ecosystems. A microbiome is the collection of microorganisms that live in a particular environment, and they’re found all over our planet. From waterways and soil to our own bodies, the diversity and genetics of a given microbiome play an enormous role in how it interacts with and influences its environment. For example, the human gut and skin host microbiomes that are implicated in human health and disease. Bioinformaticians use metagenomics to study genetic material (like DNA) isolated from environments where microbiomes are found. Using current metagenomic methods, bioinformaticians can:- Quantitate the composition and genetic diversity of microbiomes from DNA collected from a particular body organ using techniques like DNA sequence alignment against curated databases of microbial genomes
- Assemble “metagenomes,” which are the predicted genomes of individual species, assembled from the pooled DNA of multiple species isolated from a biological environment
- Detect and monitor pathogens in water or soil samples
- Correlate microbiome makeup/genetics with clinical phenotypes
Single Cell Bioinformatics: A Game Changer
Single cell bioinformatics is a cutting-edge discipline within bioinformatics that’s revolutionizing our understanding of biology. Traditional methods often involved analyzing groups of cells together, masking the differences between individual cells. Single cell bioinformatics, however, zooms in to explore the unique characteristics of each cell.Unlocking Cellular Heterogeneity
One of the primary applications of single cell bioinformatics is to unravel the heterogeneity within tissues and organs. By analyzing individual cells, scientists can discover previously hidden variations, such as differences in gene expression, cell types, and cell states. This knowledge has profound implications for understanding development, disease progression, and treatment response.Studying Rare Cell Populations
Single cell bioinformatics is invaluable when studying rare cell populations within a sample. Traditional methods may miss these rare cells, but single cell analysis can pinpoint their presence and offer insights into their function. This is particularly useful in cancer research, where identifying and targeting rare cancer stem cells can be crucial for effective therapies.Personalized Medicine
As we delve into the era of personalized medicine, single cell bioinformatics plays a vital role. By understanding the unique characteristics of a patient’s cells, including those in tumors, researchers can tailor treatments to the individual, increasing the likelihood of success while minimizing side effects.Challenges & Future Prospects
While bioinformatics, including single cell bioinformatics, has achieved remarkable milestones, it still faces challenges. Handling and analyzing the vast amount of data generated in single cell studies requires robust computational infrastructure and expertise. Additionally, ethical considerations and data privacy are essential in this era of big data. As technology continues to advance, we can expect bioinformatics to evolve as well. The integration of artificial intelligence and machine learning will streamline data analysis, making it faster and more accurate. This will open new avenues for understanding complex biological systems and accelerate the development of novel treatments. Bioinformatics is a dynamic field with far-reaching applications in various areas of biology, from genetics to environmental science. Within this field, single cell bioinformatics stands out as a game changer, offering an unprecedented level of detail and insight into the intricacies of cellular biology. As we look to the future, bioinformatics holds the key to unlocking the secrets of life, driving progress in medicine, and enhancing our understanding of the natural world. Rancho BioSciences can help you with all your data management and analysis needs. Our bioinformatics services and expertise can propel your projects to new heights. As a global leader in data curation, analysis, and visualization for life sciences and healthcare, we’re the experts you can rely on for expert biotech data solutions, bioinformatics services, data curation, AI/ML, flow cytometry services, and more. Don't hesitate to reach out to us today at (760) 642-6133 and see how we can help you save lives through data.Rancho will be in Basel this week at BioTechX, booth# 806. Stop by to hear all about our brilliant services. Saving Lives Through Data!
| Abstract
Rancho Biosciences, the premier Data Science Services company headquartered in San Diego, California, is thrilled to announce its participation in Europe's largest biotechnology congress, BioTechX, a pivotal event that serves as a bridge between pharmaceutical companies, academia, and clinicians. The event aims to foster meaningful collaborations and catalyze innovation within the biotechnology and pharmaceutical industries.
As a leading player in the field of data science, Rancho Biosciences is dedicated to revolutionizing drug development and healthcare through the application of advanced technologies and data-driven strategies. The company is proud to spotlight its key service highlights at BioTechX, which include:
AI in Drug Development and Discovery: Rancho Biosciences harnesses the power of artificial intelligence to uncover groundbreaking insights and streamline the drug discovery process. They offer pre-packaged data sets specifically designed to train AI and machine learning algorithms.
Data Integration + FAIR: Rancho Biosciences goes beyond data management; they standardize and optimize data to be analysis-ready. Their commitment to the FAIR principles (Findable, Accessible, Interoperable, and Reusable) ensures data remains valuable and accessible. Their technology enables rapid data processing without compromising quality.
Bioinformatics R&D: With a team of world-class bioinformaticians, Rancho Biosciences brings extensive experience and domain knowledge to the table. They are dedicated to training and mentoring new talent for their clients.
Single Cell Genomics and NGS: Rancho Biosciences leads the way in curating single cell data sets, including deep annotations, and they have developed an SC Data Model to harmonize thousands of data sets. They also offer data sets with fewer metadata fields optimized for AI applications, all at competitive pricing.
Data Management, Storage, and Architecture: Learn how Rancho Biosciences can help organizations implement state-of-the-art infrastructure and strategies to manage large datasets effectively. Their services encompass building Data Lakes, knowledge portals, workflows, and more to meet the unique needs of their clients.
Digital Transformation: Rancho Biosciences isn't just observing the digital evolution of biotech; they are leading it. Attendees will discover how to harness the potential of digital tools and technologies to reshape and revolutionize the biotech landscape.
Real World Evidence: Rancho Biosciences' expertise in leveraging real-world data is changing the game by enhancing clinical outcomes and informing patient care and treatment methodologies.
Analytics Platforms: Explore the depths of data with Rancho Biosciences' robust analytics tools designed to decipher complex datasets and derive actionable insights for drug development.
About Rancho Biosciences:
Founded in 2012, Rancho Biosciences is a privately held company that offers comprehensive services for data curation, management, and analysis to organizations engaged in pharmaceutical research and development. Their client portfolio includes top 20 pharmaceutical and biotech companies, research foundations, government labs, and academic groups.
For further information and press inquiries, please contact:
Julie Bryant, CEO
Email: Julie.Bryant@RanchoBiosciences.com
For more information about Rancho Biosciences and their participation in BioTechX, please visit www.RanchoBiosciences.com or stop by their booth# 806 at the event.
Source: Rancho BioSciences, LLC
Please visit Rancho next week at The Festival of Genomics, Booth# 4. Boston Convention & Expo Center, October 4 – 5.
| Abstract
Rancho Biosciences, the leading Data Science Service company, will be presenting expanded Data Science Services including our LLM work and a new product, Data Crawler that allows scientists to self-serve and find data sets they are looking for easily and quickly. The Festival of Genomics conference runs October 4-5, 2023, at the Boston Convention and Exhibition Center. Rancho’s mission of saving lives through data will be on full display through case studies, impact we have had on projects, biomarker discovery and clinical trials.
Julie Bryant, CEO and Founder, said: “Our goal is to be a partner and provide value through working efficiently with data, automating wherever possible and leveraging technologies such as AI/ML/NLP/LLM to provide high quality results with value and ROI.”
Rancho Biosciences is eager to introduce our cutting-edge services and insights to the attendees and engage with peers and pioneers alike to witness firsthand how we can turn your data into a catalyst for unmatched insights.
Why Visit Rancho Biosciences at The Festival?
Expert Insights: Delve deep into the realm of different data modalities with our scientists to better understand the latest breakthroughs and applications including single cell and spatial transcriptomics.
Tailored Solutions: Discover how our domain expertise and specialized offerings can pivot your genomics research or clinical endeavors to actionable results.
Interactive Discussions: Engage in meaningful conversations and solution-driven dialogues with our team of experts, discussing challenges and crafting a roadmap where we can build knowledge bases, data portals, unique analysis tools, workflows and pipelines.
About Rancho:
Founded in 2012, Rancho Biosciences is a privately held company offering services for data curation, management and analysis for companies engaged in pharmaceutical research and development. Its clients include top 20 pharma and biotech companies, research foundations, government labs and academic groups.
For press inquiries, please contact:
Julie Bryant
Julie.Bryant@RanchoBiosciences.com
Rancho leverages the power of LLM (Large Language Models)
| Abstract

At Rancho BioSciences, we leverage the power of large language models (LLMs) to provide a diverse range of services, enabling innovative ways to interact with data, including unstructured text, omics, and imaging data. Our expertise goes beyond the hype, delivering tangible value to our clients.
Our offerings include:
- Natural Language Processing: Gain actionable insights and enhance decision-making through advanced understanding and analysis of unstructured text data.
- Information Extraction: Streamline workflows and improve efficiency by accurately retrieving relevant information from vast data sources.
- Semantic Search: Enhance search functionality with context-aware results, ensuring accurate and relevant outcomes tailored to user intent.
- Prompt Engineering: Optimize communication and interaction with LLMs through expertly designed prompts that generate high-quality responses.
- Fine-tuning: Customize and adapt existing foundational models for seamless integration within the client's environment, maximizing performance and effectiveness.
In addition, we specialize in natural language querying (NLQ), making internal and public datasets easily accessible across large organizations. Our approach focuses on delivering tailored solutions that meet your unique requirements, driving tangible results and exceeding expectations.
RanchoBiosciences Offers CDISC-Compliant Data Curation Services Via SDTM
| Abstract

The Clinical Data Interchange Standards Consortium (CDISC) was developed to ensure healthcare, clinical, and medical research data are consistently presented and interoperable as a way of improving medical research. CDISC standards also help ensure data is FAIR (Findable, Accessible, Interoperable, and Reusable), which maximizes the data’s impact in terms of sharing capabilities, reducing R&D costs and timelines, and accelerating innovation.
The Study Data Tabulation Model (SDTM) is the CDISC-compliant standard format for data submitted to the FDA and other regulatory authorities. However, ensuring data adheres to the SDTM format can consume valuable time and resources, especially when data is derived from multiple studies.
Rancho BioSciences has developed a semi-automated workflow combining automated and manual curation, designed to flag and correct mistagged fields. This script, which first creates a preliminary tagged summary file, goes through a rigorous manual quality control protocol to ensure all domains, fields, and code lists are updated to current SDTM standards.
The resulting tagged summary file undergoes a final automated step, designed to eliminate unnecessary fields, reformat values to adhere to SDTM standards, and reorder columns per domain standards. Rancho BioSciences’ SDTM curation services create high-quality, accurate, and reliable data files to lead researchers towards actionable insights.
Rancho BioSciences is partnering with public and private research institutions
| Abstract
Rancho BioSciences is partnering with public and private research institutions to develop a comprehensive data catalog of transcriptomic studies of myeloid cells. These highly complex cells exhibit high plasticity and context-specific functions, making them difficult to study. Collecting and organizing data from existing transcriptomic studies will help researchers gain a global perspective on myeloid lineages and how they impact aging and disease.